Windows + Python + mineru API 将 PDF 批量转换成 md
使用 python 和 mineru API,将扫描版 PDF 批量 OCR,得到 markdown 及插图文件,以及后续的自动排版……

这是 Gemini 为我写的一个 Python 脚本,功能是使用 mineru 的 API,将扫描版 PDF 批量 OCR 得到 .md 文件和插图文件,以及使用 obsidian 插件 Regex Pipeline 的规则集进行批量格式化。
- 安装 python
- 申请 Mineru API
- 转换文件
- 更多用法(都可以不看)
0. 前置条件
- Windows10 或 11 操作系统
- Python ≥ 3.10 版本
1. 安装 Python
安装 Python,推荐使用 scoop。安装处理 pdf 的库:
1
pip install pyyaml requests pypdf regex
2. 申请 Mineru API
Mineru 是上海人工智能实验室推出的开源 PDF 文档解析工具,可以自己部署,或者申请官方 API 使用,目前全部免费。

Mineru 目前的限制:1. 解析文件数 5000 份/天,单份文件不超过 200 页,且不超过 200MB;2. 优先解析页数 1000 页/天,超出后排队。实测每天 > 300 本,总页数 > 10 万页未出现问题。每天 0:00 更新额度,但 “排队等待” 的状态不在 0:00 更新,会持续更久。此外,每天第一次转换时更快。
在 token管理 中申请 API,记住 Token。
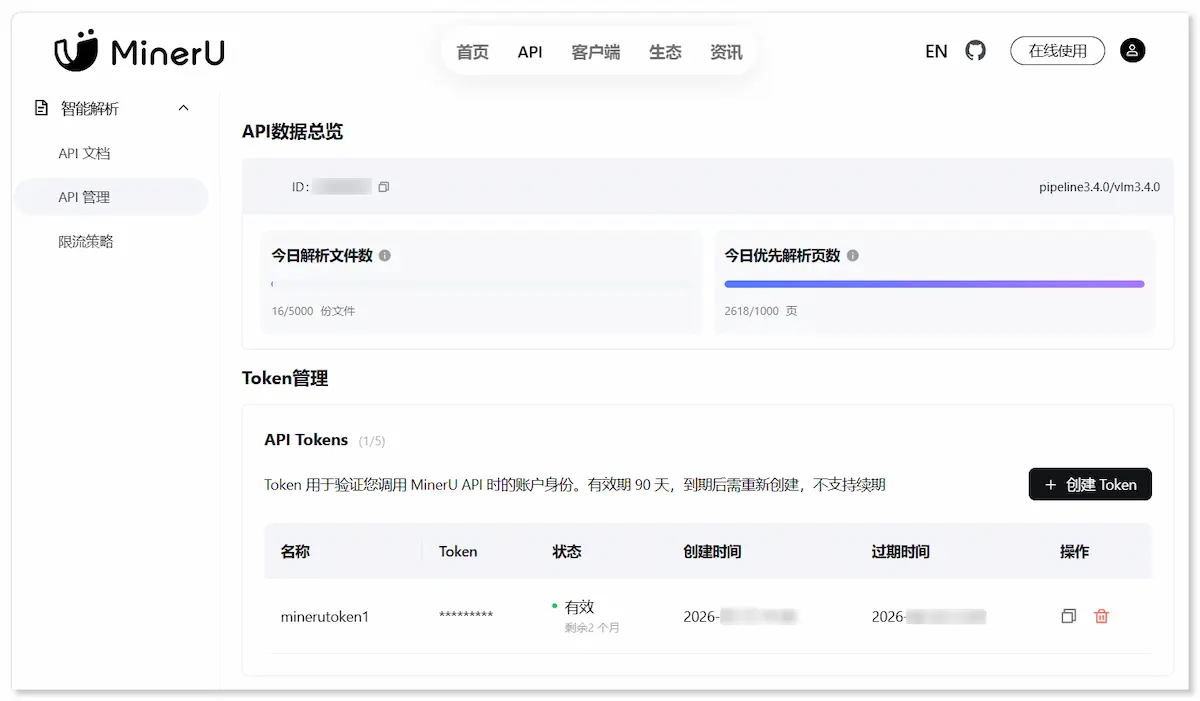
3. 将 PDF OCR 成 Markdown
在任意位置建立 minerupy 文件夹,建立目录结构,input、output、reput、src、temp 都是空文件夹。
1
2
3
4
5
6
7
8
9
10
11
12
minerupy/
├─input # 放入待处理 pdf
├─output # mineru 处理后的 .md 文件及附件出现的地方
├─reput # 正则排版后的 .md 文件及附件出现的地方
├─src
│ └─regex # regex pipeline 规则集
│ │ ├─1-排版
│ │ └─2-消除多余换行
├─temp # 自动生成,存放分割后的临时文件,会在完成后自动清理
├─default.yaml # mineru 配置,请在此填入 mineru API
├─md_regex_pipeline.py # 对 output 中的 .md 批量正则处理
└─pdf2mineru.py # 主脚本
把 default.yaml 放在 manerupy 文件夹,把 “eyJ0eXBlIjoiSlcUI……” 换成你刚刚申请的 API,如果忘了再申请一个,保存。(下面的 “ey…” 已经失效了)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
api_token: "eyJ0eXBlIjoiSlcUIiwiYWxnIjoiSFM1MTIifQ.eyJqdGkiOiI2MjQwNDU0NyIsInJvbCI6IlJPTEVfUkVHSVNURVIiLCJpc4MiOiJPcGVuWExhYiIsImlhdCI6MTc3ODU1Njk0NiwiY2xpZW50SWQiOiJsa3pkeDU3bzZ5MjJqa3BxOXgydyIsInBob25lIjoiIiwib3BlbklkIjpudWxsLDJ1dWlkIjoiNzI1ZWVkZTctYTVjZS01ZDE5LTkzMTAbYzc3MzAxMjNkYmQyIiwiZW1haWwiOiIiLCJleHAiOjE3ODYzMzI5NDZ7.4bHmvMEDTM-jHBpvFmSnWQteeBfU_Ir9lS0cFoW5a2WJrQT1xJ_D3ctb9XhvmwcilWoduY4Ts0-s6v_2cXrqzQ"
model_version: "pipeline"
is_ocr: true
enable_formula: true
enable_table: true
language: "ch"
max_pages: 200
max_size_mb: 200
split_size_mb: 150
batch_size: 50
poll_interval: 15
process_mode_threshold: 15
把 pdf2mineru.py 放在 minerupy 目录,要处理的 pdf 文件放到 input,Shift + 鼠标右键 选择“在此处打开 Powershell”,或打开 Powershell 进入这个目录(把下面的路径换成你的):
1
cd C:\Sync\project\minerupy
然后执行:
1
python pdf2mineru.py
等待转换完,你就能收获 OCR 好的 .md 文件和插图,在 output 文件夹中。
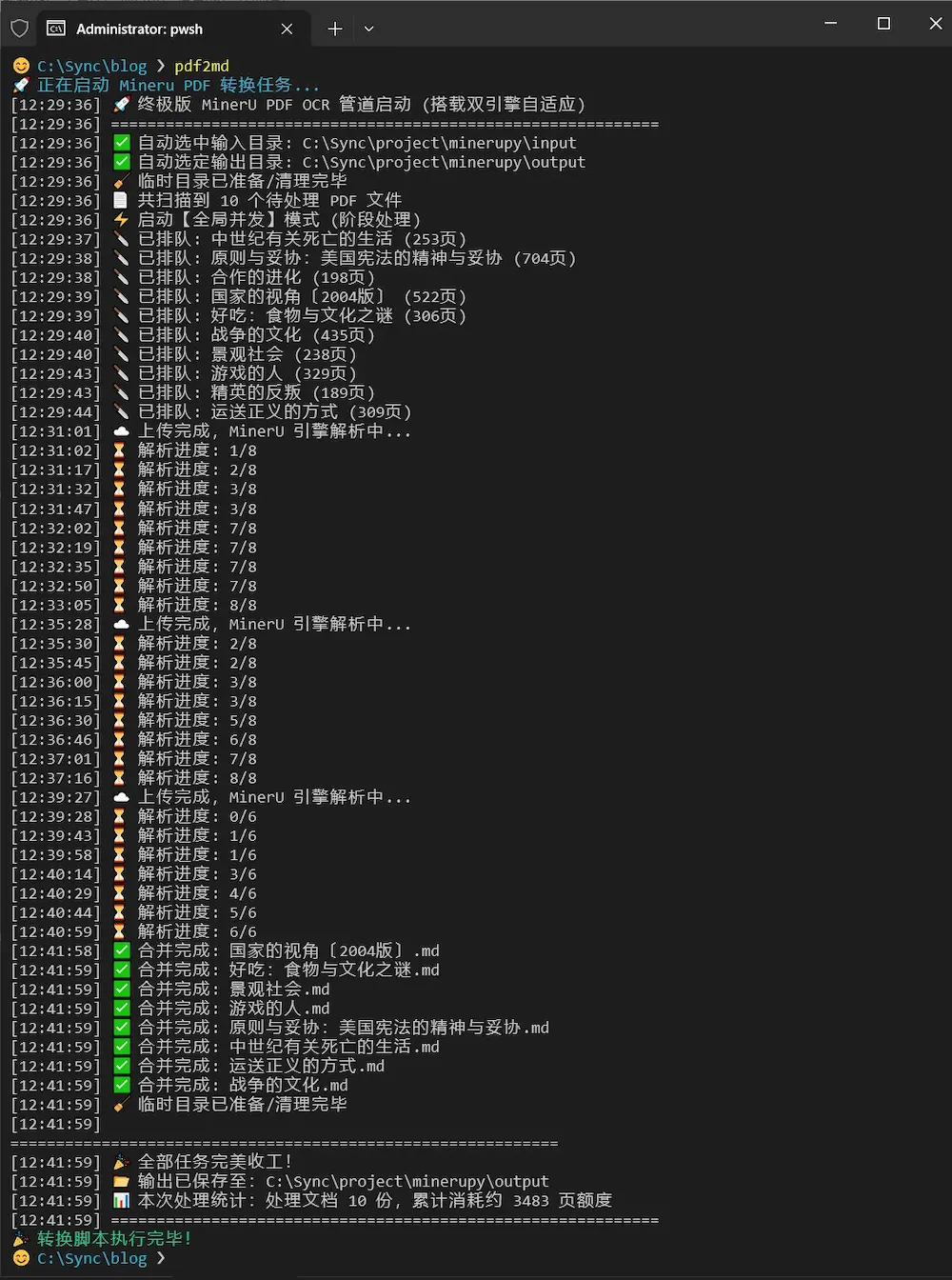
4. 更多用法:并发处理和逐本处理
你可能注意到,在文件数量 ≤15 份和 >15 时处理方式不一样。这是由 default.yaml 中
1
process_mode_threshold: 15
控制的,当文件数量 ≤ 15 时并发处理,> 15 时逐本处理。
| 模式 | 特征 |
|---|---|
| 并发处理 | 更快,切分全部 pdf 文件,全部上传 …… 可能卡在排队 |
| 逐本处理 | 更慢,切分一个 pdf 文件,上传 mineru 处理,返回文件,开始下一个文件……一定能得到部分文件 |
mineru 排队很久时不一定成功,这时逐本处理更安全。如果你把 15 改成 1,就是默认逐本处理。
5. 更多用法:指定输入输出目录
pdf2mineru.py 默认把同位置的 input、output 作为输入输出目录,也能显式地指定输入目录、输出目录。
1
python pdf2mineru.py -i "C:\图书馆\原始PDF" -o "C:\我的图书\OCR结果"
没有指定的就是默认的,例如
1
python pdf2mineru.py -i "C:\图书馆\原始PDF"
会处理目录“原始 PDF”中的 pdf 文件,将处理后的文件保存到 pdf2mineru.py 同级的 output 文件夹。
pdf2mineru.py 默认处理多层文件夹,例如“./input/文件夹-1/filename.pdf”,会输出“./output/文件夹-1/filename.md”。
6. 更多用法:排版流水线
目录中还有一个 md_regex_pipeline.py 文件,功能是读取 ./src/regex 目录下的正则表达式规则文件,批量格式化 output 目录中的 .md 文件,将格式化后的文件及附件保存到 reput 文件夹。
md_regex_pipeline.py 只能读取单层目录中的规则文件,目的是控制规则集。例如:
1
2
3
4
5
6
7
8
9
10
……
├─src
│ └─regex # regex pipeline 规则集
│ │ ├─novel
│ │ │ ├─01-小说排版
│ │ │ ├─02-嗅探章节
│ │ │ └─03-消除多余换行
│ │ ├─01-排版
│ │ └─02-消除多余换行
……
当你执行:
1
python md_regex_pipeline.py
默认按 “./src/regex” 下的 01-排版、02-消除多余换行 依次处理 output 中的 .md 文件。
执行:
1
python md_regex_pipeline.py -r novel
则会切换成 novel 文件夹下的 01-小说排版、02-嗅探章节、03-消除多余换行 规则。这样可以自己在 ./src/regex 下建立文件夹,通过 -r <文件夹名称> 或 -r ./src/regex/<文件夹名称> 切换规则,通过规则的增删组合出不同的排版。同样的,也可以通过 -i 、-o 指定输入输出目录。
规则文件按文件名顺序套用,因此建议按 “01-”、“02-” 命名。
规则文件使用 Obsidian 插件 Regex Pipeline 的写法,于是在 Obsidian 中测试好的规则可以直接复制到 regex 目录下使用。格式如下:
1
"SEARCH"->"REPLACE"
例如
1
2
3
4
5
6
"「"->"“"
"」"->"”"
"^(第)([零〇一二三四五六七八九十百千万a-zA-Z0-9]{1,7})([章节卷集部篇回幕])"->"## $1$2$3"
"\n{3,}"->"
"
第 1、2 行规则将繁体引号 「」 换成 “”,第 3 行将 “第 x 章” 这类的内容换成 markdown 的二级标题,第 4 行是将连续 3 个换行替换成两个换行,这里有 Regex Pipeline 唯一特殊的语法——输出中的换行不能用 \n,只能用 Enter 换行表示,这是 Obsidian 的限制导致的。
默认附加 gm 标志以支持多行匹配。可以让 AI 看一下  obsidian-regex-pipeline 给你写规则,逐渐积累适合你的规则集,并优化正则处理顺序。
obsidian-regex-pipeline 给你写规则,逐渐积累适合你的规则集,并优化正则处理顺序。
7. 更多用法:Powershell functions
你可能注意到,上面我输入的是
1
pdf2md
这是 Powershell 的 alias(别名)功能,可以在 Powershell 中输入你自定义的命令来执行某些命令。比如 “pdf2md” 自动跳转到 “C:\Sync\project\minerupy” 目录并执行python pdf2mineru.py 。
只需要在 Powershell 中输入
1
$PROFILE
打开 C:\Users\<用户名>\Documents\PowerShell\Microsoft.PowerShell_profile.ps1 粘贴以下代码,”C:\Sync\project\minerupy” 换成你的位置,保存。
1
2
3
4
5
6
7
8
9
10
function pdf2md {
Write-Host "🚀 正在启动 Mineru PDF 转换任务..." -ForegroundColor Cyan
Push-Location "C:\Sync\project\minerupy"
try {
python pdf2mineru.py $args
} finally {
Pop-Location
}
Write-Host "🎉 转换脚本执行完毕!" -ForegroundColor Green
}
然后刷新 Powershell 环境,比如关闭,任意目录下打开。然后就可以用 pdf2md 触发处理了。代码中的 $args 可以传递参数,所以你也可以 pdf2md -i <输入目录> -o <输出目录>。
代码中的 Push-Location 表示跳转到某个目录,try 后面那行是要运行的命令,所以你可以在 Microsoft.PowerShell_profile.ps1 末尾再增加一段 “function pdf2mdr……”,改一改,通过 pdf2mdr 触发正则处理。
8. 更多用法:pdf 文件右键菜单增加“2md” 以及有新 pdf 时自动触发运行
越写越多,超过了主题范围,这里不再详细写了。
问一下 AI,ContextMenuManager 搭配 vbs script 在右键菜单增加项目,静默运行上面的脚本。通过 .NET 的 FileSystemWatcher 监控指定文件夹,有 pdf 文件变动时触发运行上面的脚本。